Apple Silicon Compute Units
Apple
Apple Silicon 上有四块硬件可以进行矩阵乘法,分别是CPU,GPU,ANE(Apple Neural Engine)和专门的Coprocessor。
| hardware | Introduction |
|---|---|
| CPU | 标准ARMv8 SIMD/NEON向量指令,128bits位宽 |
| GPU | Metal Compute Shaders |
| ANE | 神经处理单元 |
| AMX | 苹果没有官方文档中说明AMX指令,是特殊的加速执行单元 |
AMX
Apple未公开的AMX指令,从CPU发出,在特殊的加速器执行单元上执行,Apple 官方既未记录也不支持这些指令,这样就不需要保持与已编译软件的向后兼容性。不同版本的芯片可能具有不同的AMX指令,M2相对于M1增加了bf16支持。
下图取自于废弃的专利US20180074824A1,这是 AMX 的一个很好的单图摘要。考虑一个 32x32 计算单元网格,其中每个单元可以执行 16 位乘法累加,或者 2x2 单元子网格可以执行 32 位乘法累加,或者 4x4 子网格可以执行 64 位乘法累加。为了提供该网格,有一个 $X$ 寄存器池,每个寄存器包含 32 个 16 位元素(或 16 个 32 位元素,或 8 个 64 位元素),还有一个 $Y$ 寄存器池,同样包含 32 个 16 位元素(或 16 个32 位元素,或 8 个 64 位元素)。一条指令可以执行完整的外积:将 $X$ 寄存器的每个元素与 $Y$ 寄存器的每个元素相乘,并与相应位置的 $Z$ 元素累加。 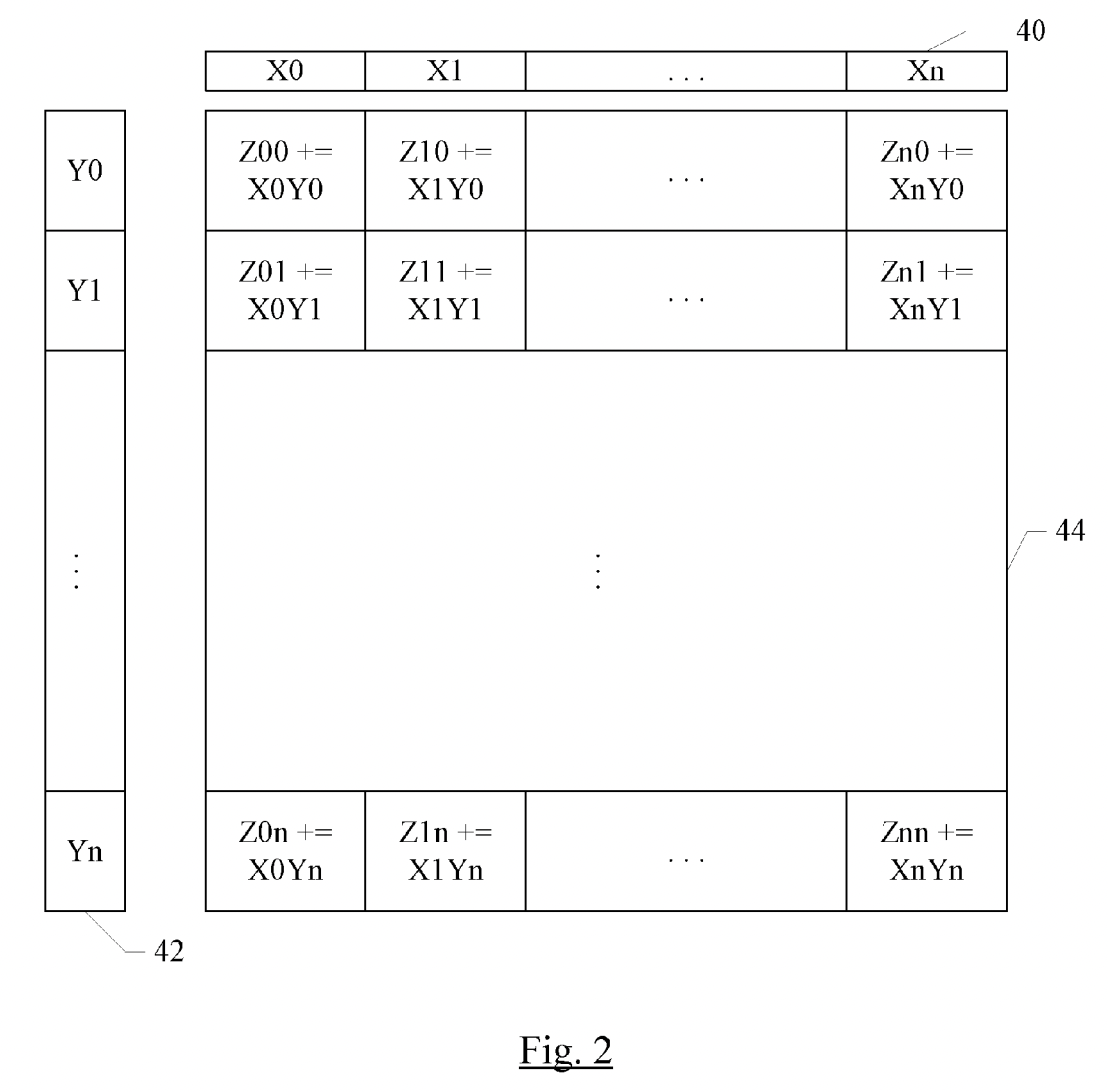
32x32 网格的单行也可用于在 $X$ 和 $Y^T$ 之间执行向量运算(而不是矩阵运算)。
尽管 Apple 没有记录将计算分派到 AMX block的指令,但第三方应用程序可以通过 Apple 的 Accelerate 框架使用 AMX block,该框架实现了行业标准 BLAS 接口。因此,BLAS 矩阵乘法函数会自动加速。
ANE
Apple Neural Engine (ANE) 也跟AMX指令一样是一个undocumented enigma,但是我们可以通过Apple的coremltools Python库使用它,这个库可用于将模型转换为Apple的MLProgram格式,还可以在ANE上调用推理。需要从源代码构建库才能进行推理,但模型转换可以通过 pip 安装进行。
根据 Apple 的说法,ANE 提供了 11TOPS,大概是 INT8 的性能,但是我们无法调用 INT8 操作(CoreML 目前仅在 ANE 上公开 FP16 操作)。因此,我们可以假设 ANE 上的最大 5.5 TFLOPS FP16。这在 A14/M1/M1 Pro/M1 Max 中是相同的,因为它们具有相同的 16 核 ANE。值得注意的是,我们不能强制 CoreML 模型在 ANE 上运行,只能指定 CPU、CPU/GPU 或 CPU/GPU/ANE 的约束。因此,有时模型可能在 GPU 而不是 ANE 上运行,并且开发者无法控制 CoreML 做出的这一决定。
Core ML针对不同的处理器使用了以下的框架: - CPU: BNNS,或基本神经网络子程序,Accelerate.framework 的一部分 - GPU: Metal Performance Shaders (MPS) - ANE: 私有框架
Core ML 可以拆分模型,以便一部分在 ANE 上运行,另一部分在 GPU 或 CPU 上运行。当它这样做时,它会在这些不同的框架之间切换。iPhone、iPad 和 Apple Silicon Mac 具有共享内存,这意味着 CPU、GPU 和 ANE 都使用相同的 RAM。共享内存的优点是我们不需要将数据从一个处理器上传到另一个处理器。但这并不意味着处理器之间的切换没有成本:数据仍然需要转换为合适的格式。例如,在 GPU 上,数据需要首先放入texture objec中。
GPU
GPU是可编程的,可以运行用户定义的计算内核(所谓的shaders)。这使得 GPU 足够灵活,可以运行多种机器学习模型。M1 的 8 核 GPU 的计算性能为 2.6 TFLOPS,大约是 M1 AMX 单元性能的两倍。PyTorch通过 Apple 的 Metal API 引入了对 Apple M GPU 的支持。各种 PyTorch 操作已作为自定义 Metal shaders实现,并使用 Apple 自己的 Metal shaders(包含在 Metal Performance Shaders 框架中)。对于支持的操作,在 PyTorch 中使用 Apple Silicon GPU 就像在新的 mps 设备上放置张量或模块一样简单。例如,可以通过以下方式在 GPU 核心上完成矩阵乘法:
1
2
3
4
5
6
7
>>> import torch
>>> u = torch.rand((10, 20), dtype=torch.float,
device=torch.device("mps"))
>>> v = torch.rand((20, 10), dtype=torch.float,
device=torch.device("mps"))
>>> torch.matmul(u, v).device
device(type='mps', index=0)
由于AMX仅加速矩阵乘法,因此非线性计算成为最大的计算瓶颈。这对于 GPU 推理来说不是问题,因为非线性是在 GPU 上并行计算的。
CPU
Arm CPU 上的高性能计算一般指的是 Neon 指令。Neon 指令就是一种基于SIMD思想的ARM技术,提供128-bit宽的向量运算(vector operations),本质是通过短向量指令来加速浮点计算。这和x86上的SSE属于同一类技术。
Benchmark
需要注意的是这些数据摘录自我浏览的技术博客,并不是很严谨。
AMX matrix multiplication blocks
所有 Apple M CPU 都至少有一个称为“AMX 块”的矩阵乘法协处理器。 如上所言,AMX 基本上没有文档记录。例如,尚不清楚 Apple M CPU 的节能核心集群是否有自己的 AMX 块。但是,我们可以通过对 AMX 块进行基准测试来推断它们的各种属性。下表列出了使用 gemm-benchmark 测量的 768x768 矩阵在各种 CPU 上以 TFLOPS(每秒万亿次浮点运算)计算的矩阵乘法性能:
| Threads | M1 | M2 | M1 Pro/Max | M1 Ultra | Ryzen 5950X |
|---|---|---|---|---|---|
| 1 | 1.3 | 1.5 | 2.1 | 2.2 | 0.1 |
| 2 | 1.2 | 1.6 | 2.6 | 3.4 | 0.3 |
| 4 | 1.0 | 1.7 | 2.7 | 3.8 | 0.6 |
| 8 | 1.3 | 1.6 | 2.5 | 4.3 | 1.0 |
| 12 | 1.2 | 1.5 | 2.4 | 4.3 | 1.6 |
| 16 | 1.2 | 1.4 | 2.4 | 4.4 | 1.9 |
| Largest speedup compared to M1 | 1.0 | 1.3 | 2.1 | 3.4 | 1.5 |
从表格的数字中可以收集到一些有趣的信息:
- 性能不会随着线程数量的增加而提高。因此,AMX block不是各个 CPU 内核的一部分。
- M1、M1 Pro 和 M1 Ultra 分别拥有 1、2 和 4 个 performance core 集群。矩阵乘法性能随着性能核心集群数量的增加而增加(请参阅与 M1 行相比的最大加速)。这表明每个性能集群都有一个 AMX block 。
- AMX block速度很快。单个 AMX block 具有与 9 个 Ryzen 5950X 核心相同的矩阵乘法性能。
Metal Performance Shaders in spaCy and Thinc
spaCy 使用 Thinc 作为其机器学习库。Thinc 是一个轻量级深度学习库,还支持 PyTorch 和 Tensorflow 等其他框架中定义的层。借助 Thinc 8.1 和 PyTorch 1.13,我们可以在 Apple Silicon GPU 上执行 Transformer 推理。下表显示了在各种 Apple Silicon Mac 上使用 de_dep_news_trf Transformer 模型注释德语文本的速度(以每秒字数 (WPS) 为单位):
| Machine | CPU cores | GPU cores | AMX (WPS) | GPU (WPS) | Speedup |
|---|---|---|---|---|---|
| Mac Mini M1 | 4P/4E | 8 | 1180 | ==2202== | 1.9 |
| MacBook Air M2 | 4P/4E | 10 | 1242 | ==3362== | 2.7 |
| MacBook Pro 14” M1 Pro | 6P/2E | 14 | 1631 | ==4661== | 2.9 |
| MacBook Pro 14” M1 Max | 8P/2E | 32 | 1821 | ==8648== | 4.7 |
| Mac Studio M1 Ultra | 16P/4E | 48 | 2197 | ==12073== | 5.5 |
| Ryzen 5950X + RTX 3090 | 16 | 328 (Tensor cores) | 1879 (CPU) | ==18845== | 10.0 |
该基准测试显示,与 AMX block相比,使用 Apple Silicon GPU 时速度显著提高,GPU 上的速度高达每秒 8648 个字,而 M1 Max 上的 AMX block上的速度为每秒 1821 个字。 M1 Max 的推理性能几乎是 NVIDIA RTX 3090 的一半。
8 个 M1 GPU 核心的计算性能估计约为一个 AMX block的两倍,但事实证明,M1 Pro 上的推理速度是其两倍多,尽管该特定模型仅具有两个采用 AMX 的 performance core 集群和 14 个 GPU 核心。原因是 AMX 仅加速矩阵乘法,而 GPU 还加速其他内核,包括 GELU 和 Softmax 非线性。
AMX2 与 NEON
Eigen 是一个相当易于使用的C++线性代数算法高级模板库,我们可以将其封装为更高级的C++中使用。BLIS(类似 BLAS 的库)也遵循类似的范例,其中“最内部”微内核是针对特定架构的高度手动优化的组件,并形成可以用更可移植的代码编写的更高级别计算的基础。然而,BLIS 在ARM/NEON 上的微内核支持并不好。相比之下Eigen可能更加成功。在这里主要使用 AMX2 和 Eigen 的 Neon 优化版本来评估大小为 1000 的简单 SGEMM。实验结果显示在单精度浮点计算上,AMX2的性能是NEON的两倍多。
Reference
Comparing Apple’s M1 matmul performance – AMX2 vs NEON
Fast transformer inference with Metal Performance Shaders
How to get 1.5 TFlops of FP32 performance on a single M1 CPU core
Counting cycles and instructions on the Apple M1 processor
BLAS (Basic Linear Algebra Subprograms)
Understanding the Hardware Capabilities of Apple’s flagship SOC
GEMM: From Pure C to SSE Optimized Micro Kernels